
11 Nov 2019
Back in January, I was observing that having free for all innovation on congestion control might be problematic. I was invited to discuss that in front of the TCPM working during the IETF meeting in Montreal, this July. After presenting the issue in a few slides, I saw a number of TCP experts line at the microphone and explain me that I was wrong. Their main argument was that if this was true, the Internet would have collapsed long ago due for example to video streaming, or to server using very large initial congestion windows. OK. So I went on to tune the congestion control algorithms used in Picoquic, my implementation of the Quic protocol. The first step was to make my implementation of Cubic actually work.
The Quic draft for recovery specifies use of the Reno congestion algorithm, but Reno is old and does not perform very well on high speed high latency links. Cubic was developed to provide better stability and scalability. It is implemented in a number of TCP stacks, including Windows and Linux, and has probably become the most used algorithm on the Internet – at least until BBR catches on. Cubic is described in several academic papers and in RFC 8312, and I based my initial implementation on the text in that RFC. It kind of worked, but there were three issues: implementation of the TCP friendly algorithm, making Hystart work with noisy RTT measurements, and recovery from spurious retransmissions.
The RFC explains that Cubic, like Reno, can operate in two modes: slow start and congestion avoidance. In congestion avoidance mode, Cubic uses a time-base formula to grow the congestion window as:
W_cubic(t) = C*(t-K)^3 + W_max
The window grows relatively fast at the beginning of the interval, stays relatively stable when “t” is near the value “K”, and then grows quickly to probe for available bandwidth. During the initial part of that period, the window could well be lower than what would have been computed using TCP Reno. The RFC describes that as the “TCP friendly region”. The RFC suggests computing the window that Reno would have found and using it if it is larger than what the Cubic formula provides. I implemented that, and the results were surprising. The traces showed that the congestion window was swinging widely, being reevaluated after pretty much every received acknowledgement. After a bit of head scratching, I concluded that this was caused by the formula used in the draft to compute the “TCP friendly” window:
W_est(t) = W_max*beta_cubic + [3*(1-beta_cubic)/(1+beta_cubic)] * (t/RTT)
This formula captures the way New Reno grows the TCP window by one packet per RTT, but the text in the RFC does not specify what the RTT value shall be. In my initial implementation, I simply used the “smoothed RTT” computed by the Quic recovery algorithm, but this smoothed RTT is of course not constant. The randomness in the RTT measurement causes it to vary up and down, and caused inversely proportional changes in the congestion window. I suppose that we could use an arbitrary constant value instead of the smoothed RTT, such as maybe the same RTT value used to compute the Cubic coefficient K, but then the formula would not describe the actual result of the New Reno evaluation. In my code, I fixed the issue by simply running the New Reno computation in parallel to Cubic, processing the received acknowledgements and increasing the window accordingly.
The RFC mentions that implementations might use the hybrid slow start algorithm usually referred to at Hystart. The algorithm itself is not defined in the RFC, but can be found in a research paper. In addition to exiting slow start on first packet loss, the way new Reno does, Hystart will also monitors the evolution of the RTT to estimate the bandwidth and the target window, and exit slow start before any packet is lost. This can result in connections that perform very well and often conclude without losing any packets. In my initial tests, using Hystart resulted in significant performance improvements most of the time. However, there were also cases in which Hystart would exit slow start too soon, resulting in degraded performances. A look at RTT measurements explain why:
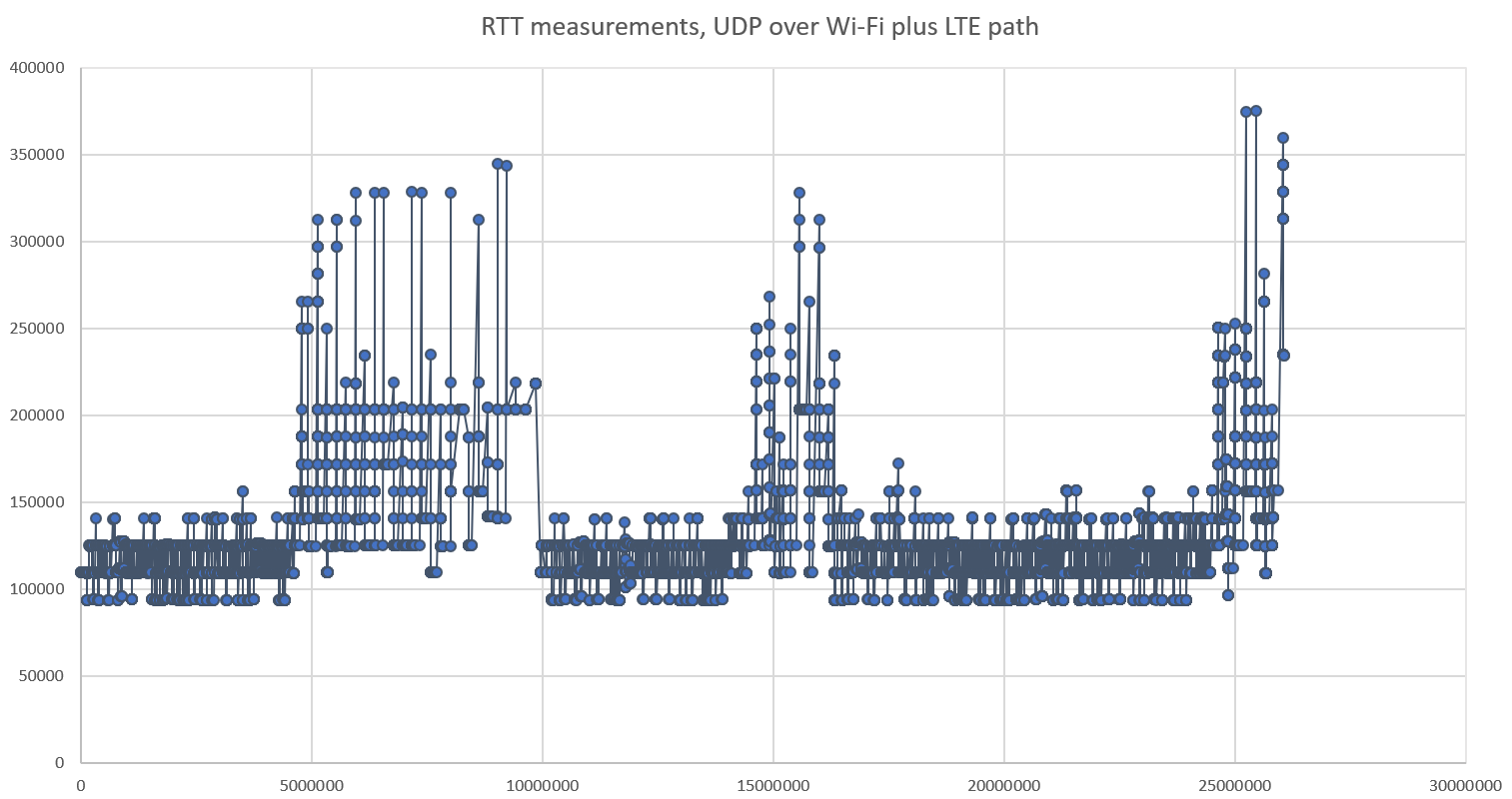
The graph above shows a series of RTT measurements. The X axis shows the time of the measurement since the start of the session, the Y axis shows the RTT measured as the delay between sending a packet and receiving the acknowledgement – all values are in microseconds. We can visually identify 6 intervals in the session: 3 intervals in which the RTT remains low, and 3 intervals during which congestion causes higher delays. The interesting part is the high variability of the measurements during the “low delay” intervals – it might be due to specificities of the Wi-Fi and LTE links used in the experiment, or to queuing delays in the UDP sockets.
Traditionally, delay-based algorithms like Hystart do not account for this variability. They typically reference an “RTT min” measured as the lowest delay since the beginning of measurements. When the measured delay is larger than the minimum, they infer the beginning of congestion. But if the delay varies somewhat randomly as in the example above, the RTT min will ratchet down each time a lucky packet experience low delay, and the congestion will be detected too soon when an unlucky packet got a randomly high delay.
My solution was to implement two filters. Instead of measuring the RTT “min”, I measure an RTT “mode” as:
RTTmode = min (RTTmode, max(RTTn, …, RTTn-4))
Then, I would detect congestion when 5 consecutive RTT measurements are all larger than the mode. This stabilized my implementation of Hystart, and greatly reduced the number of “false exit”.
If you look closely at the graph of RTT above, you will see a number of vertical bars with multiple measurements happening at almost the same time. This is a classic symptom of “ACK compression”. Some mechanism in the path causes ACK packets to be queued and then all released at the same time. I copied in my implementation the packet repetition algorithms described in the Quic recovery specification, but the algorithms were not designed to deal with this kind of ACK compression. The queuing of the acknowledgment caused packets to be retransmitted too soon. The ACK was received some time later, causing the retransmission to be classified “spurious”, but since the Cubic RFC does not say anything about spurious retransmissions. I had not written any code to deal with it. The results were not good:
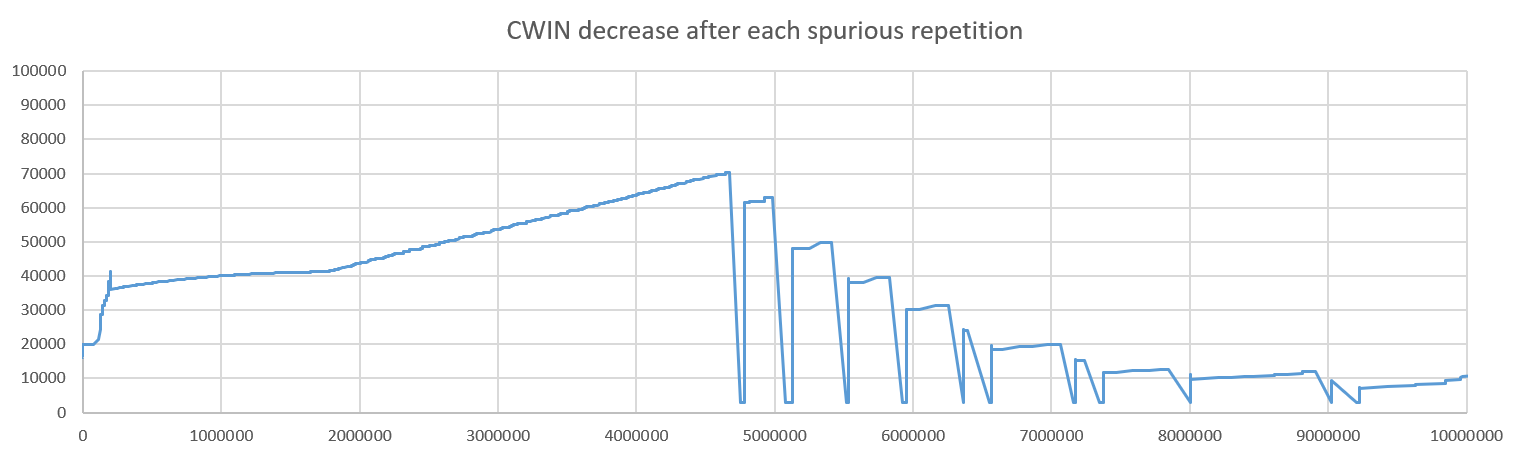
Each time a packet is retransmitted, the Cubic algorithm exits the congestion avoidance mode and recompute its coefficients. We see in the graph that each spurious retransmission is mistaken as a congestion signal, causing the congestion window to “ratchet down”. The performances become really bad.
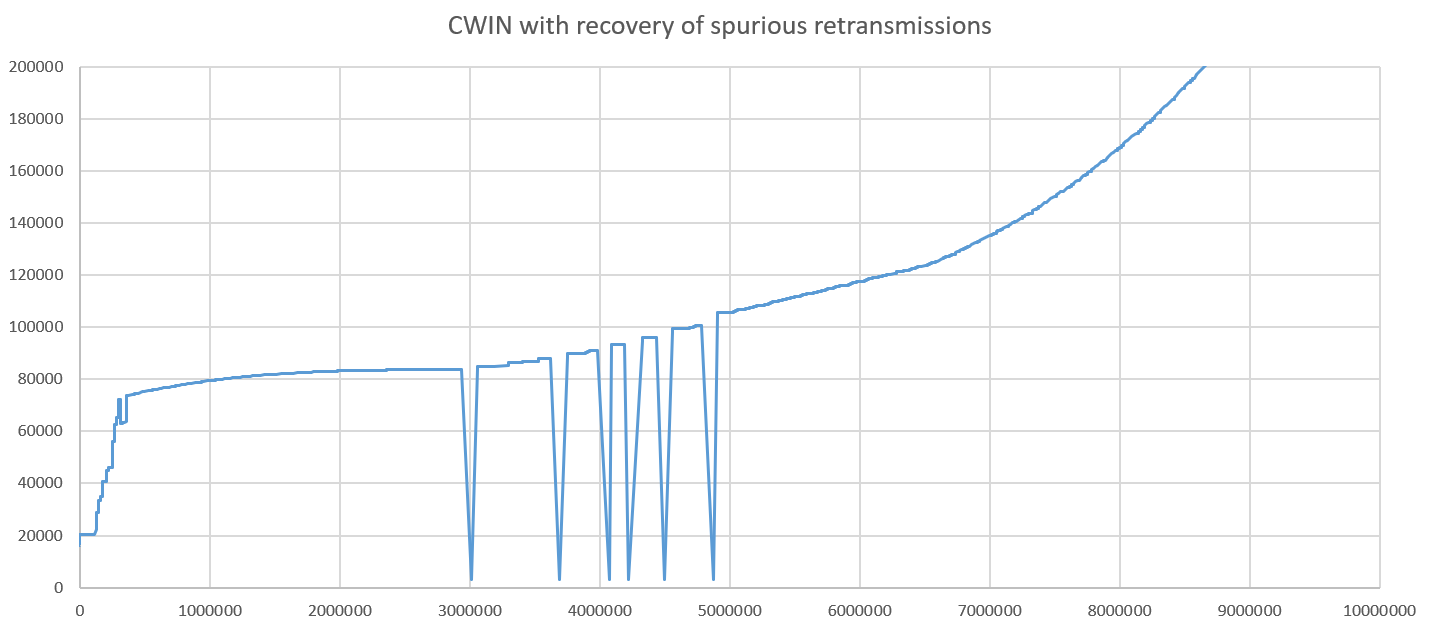
The solution is to implement some form of spurious retransmission recovery. Supposed that a retransmission caused the congestion window to shrink and is later recognized as spurious. Spurious retransmission recovery will reset the congestion control to the state that it would have if the retransmission did not happen. In Cubic, that means restoring key parameters like the coefficients K and Wmax or the beginning of the epoch to their value before the retransmission. After doing that, Cubic performs much better:
During the Quic Interop sessions, we do tests comparing the performance of Quic and HTTP3 to the performance of a classic HTTP2 server. On my server I do that by comparing the performance of Picoquic to that of an Apache2 server running on the same machine. The test is officially described as: Download objects named 5000000 and 10000000 on separate connections over both HTTP/2 and HTTP/3 (0.9 if H3 not available). Overall transfer time should be no worse than 10% slower than HTTP/2.
With the fixes described above, the Quic server is definitely not 10% slower than the HTTP server. In fact, it is close to twice faster. Innovation is good!