
14 Feb 2021
I authored two drafts proposing two different solutions for Multipath QUIC: QUIC Multipath Negotiation Option; and, in collaboration with colleagues at Ali Baba, Multipath Extension for QUIC. Apart from some details that could easily be aligned, the main difference is that the “negotiation option” maintains the property of QUIC Transport to have a single packet number space for all application packets while the “multipath extension for QUIC” specifies that there will be a specific packet number space for each path. The implementation in picoquic described in a previous blog supports both options.
Supporting different number spaces per path is significantly harder to implement than keeping the single number space design adopted so far in QUIC. In my code, I use two configuration flags for the simple version and the version that uses multiple number spaces. The simple flag is referenced 13 times, the multiple number space flag 50 times. If I remove the initial declaration, the test code, the logging code and the negotiation of transport parameters, the simple flag is used in a total of 6 tests, but I find tests of the multiple number space flag at 41 places. All 6 tests that reference the simple flag also reference the multiple number space flag, for the following functions:
The other 35 flag tests are required to manage one name space per path. When packets are received, the acknowledgements are prepared in a “per path” structure instead of the “per application context” structure, the format of the acknowledgement frames changes, and the code must take care to send acknowledgements for all number spaces. Similarly, when packets are sent, the code needs a “per path” structure to keep track of packets in flight, manage retransmissions, and detect spurious retransmissions.
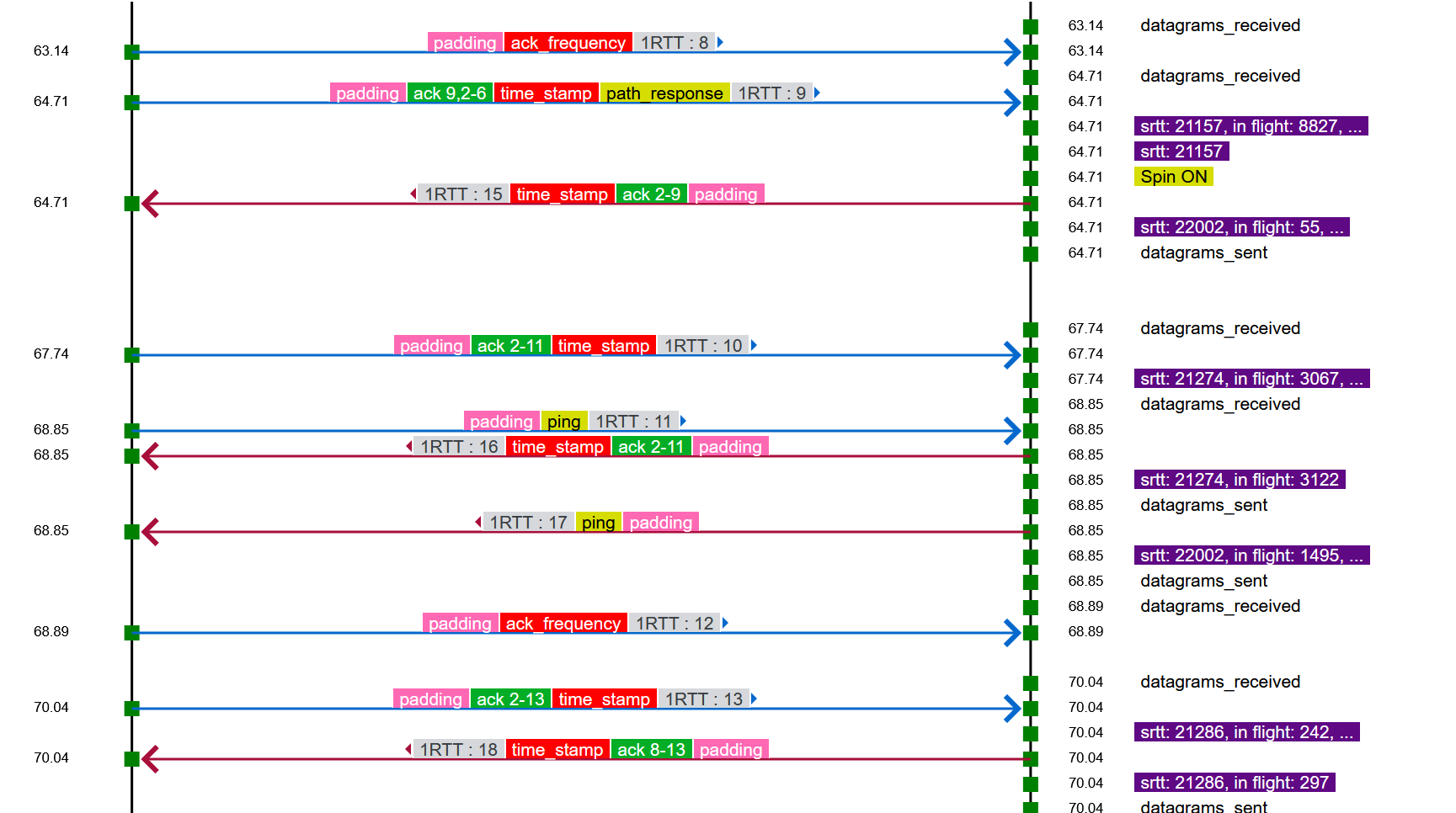
In single path QUIC, the packet numbers are monotonically increasing and can be used as a pseudo clock. Removing that property has interesting consequences, as shown in the messed up representation of QUIC logs mentioned in a previous blog. (Using a single sequence number results in simpler visualizations, as seen in the picture above.) In many places, tests on sequence numbers may be replaced by tests on timestamps, and in other per sequence space numbers should be used. For packet encryption, since per path packet numbers are not unique, a 96 bit packet number is computed by concatenating path-ID and packet number, and is then used to guarantee uniqueness of the AEAD nonce. This extra code required a parallel push request to the Picotls library. Adding per path sequence number does add lots of code complexity.
The additional complexity has a direct implication on test coverage. Most of the code paths used in the single number space variant are also exercised by the single path tests. In that variant, additional tests are only required for multipath execution. In contrast, the multiple number space variant creates new code paths even for single path scenarios, such as for example 0-RTT transmission. To maintain test coverage, I will need to repeat most single path tests with the multiple number space option enabled.
The main argument for adding number space per path is efficiency: efficiency of the packet encoding, and specifically of the encoding of acknowledgements; and efficiency of the loss recovery processes. If packets are numbered “per path”, we can then adopt an unmodified per path version of the RACK algorithm used by QUIC for packet loss detection. That is true, and this is an area in which the simple multipath option requires specific code changes. When detecting packet losses, the RACK algorithm compares the packet’s sequence number and send time to those of the last packet acknowledged. If the packet was sent before the most recently acknowledged packet but has not been acknowledged yet, that packet was either lost or delivered out of order. RACK checks both time differences and sequence number differences against thresholds, and if those thresholds are exceeded the packet can safely be considered lost.
If the paths have different latencies or experience different delays, the simple multipath option will result in out of order deliveries, with time differences and sequence number differences that can widely exceed what RACK expects. In my implementation, I fixed that by keeping track of the path over which a packet was sent, and of the last packet acknowledged for each path. When deciding whether a packet can be lost, the code compares times and sequence numbers to the last packet acknowledged for the path, not to the last packet acknowledged overall.
The other potential issue with the simple multipath version is the size of the acknowledgement packets. Out of order deliveries translates into many “holes” in the list of packets received. QUIC acknowledgement frames can encode multiple ranges of received packets, but there are limits to how many ranges we want to encode per acknowledgement. Performance functions like UDP GSO mitigate that somewhat, as the code will send trains of consecutive packets from the same path, reducing the overall number of ranges. However, there might still be a problem when there is a large discrepancy between the latencies of the two paths, for example when balancing traffic between a terrestrial and a satellite link.
The extent of that problem is not clear. The current test suite includes the case of a 10 Mbps satellite link in parallel with a 1 Mbps terrestrial link, and the results for both multipath variants are similar. It is possible that different test configurations will produce different results, but at this stage it is speculation. It is also possible that simple tweaks in the transmission of acknowledged ranges or in the scheduling of packets would solve the issue. There will be some added complexity, but I believe this added complexity will be much less than the overall complexity of managing multiple packet number spaces. That same complexity will also be required in the number per path version if we want to support zero-length connection ID, which is an important feature.
In QUIC, the length of the connection ID is chosen by the destination node. Servers generally require use connection IDs that are long enough to manage proper load balancing in a server farm. Clients that do not establish multiple connection to the same server do not need that, because they can identify the connection context from the combination of source and destination addresses and ports. Such clients can decide to use zero-length connection identifiers. There will be less overhead in packets received from the server, resulting in slightly better performance. Imposing the use of full connection ID in multipath communication will bring that overhead back, resulting in a performance trade-off.
In conclusion, we have a trade-off. Managing separate number spaces for each path increases the complexity of the implementation but may result in slightly more efficient management of acknowledgements. Keeping a single number space for all spaces is much simpler but may require a few tweaks in the management of acknowledgements. The single number space variant supports use of zero length connection identifiers, while the separate number space variant does not. The multiple space variant requires adding a number of code paths that are not exercised by the “single path” tests, which has an effect on code safety. Overall, after implementing both options, I prefer the single-space variant but I am waiting to hear the opinions of other developers.